Note
Go to the end to download the full example code.
Run LassoCV for cross-validation on the Leukemia dataset¶
The example runs the LassoCV scikit-learn like estimator using the Celer algorithm.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import KFold
from celer import LassoCV
print(__doc__)
print("Loading data...")
dataset = fetch_openml("leukemia")
X = np.asfortranarray(dataset.data.astype(float))
y = 2 * ((dataset.target == "AML") - 0.5)
y -= np.mean(y)
y /= np.std(y)
kf = KFold(shuffle=True, n_splits=3, random_state=0)
model = LassoCV(cv=kf, n_jobs=3)
model.fit(X, y)
print("Estimated regularization parameter alpha: %s" % model.alpha_)
Loading data...
/home/circleci/.local/lib/python3.8/site-packages/sklearn/datasets/_openml.py:311: UserWarning: Multiple active versions of the dataset matching the name leukemia exist. Versions may be fundamentally different, returning version 1.
warn(
/home/circleci/.local/lib/python3.8/site-packages/sklearn/datasets/_openml.py:1022: FutureWarning: The default value of `parser` will change from `'liac-arff'` to `'auto'` in 1.4. You can set `parser='auto'` to silence this warning. Therefore, an `ImportError` will be raised from 1.4 if the dataset is dense and pandas is not installed. Note that the pandas parser may return different data types. See the Notes Section in fetch_openml's API doc for details.
warn(
Estimated regularization parameter alpha: 160.15306704065625
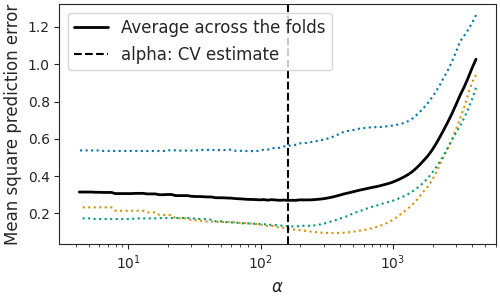
Display results
plt.figure(figsize=(5, 3), constrained_layout=True)
plt.semilogx(model.alphas_, model.mse_path_, ':')
plt.semilogx(model.alphas_, model.mse_path_.mean(axis=-1), 'k',
label='Average across the folds', linewidth=2)
plt.axvline(model.alpha_, linestyle='--', color='k',
label='alpha: CV estimate')
plt.legend()
plt.xlabel(r'$\alpha$')
plt.ylabel('Mean square prediction error')
plt.show(block=False)
Total running time of the script: (1 minutes 15.635 seconds)